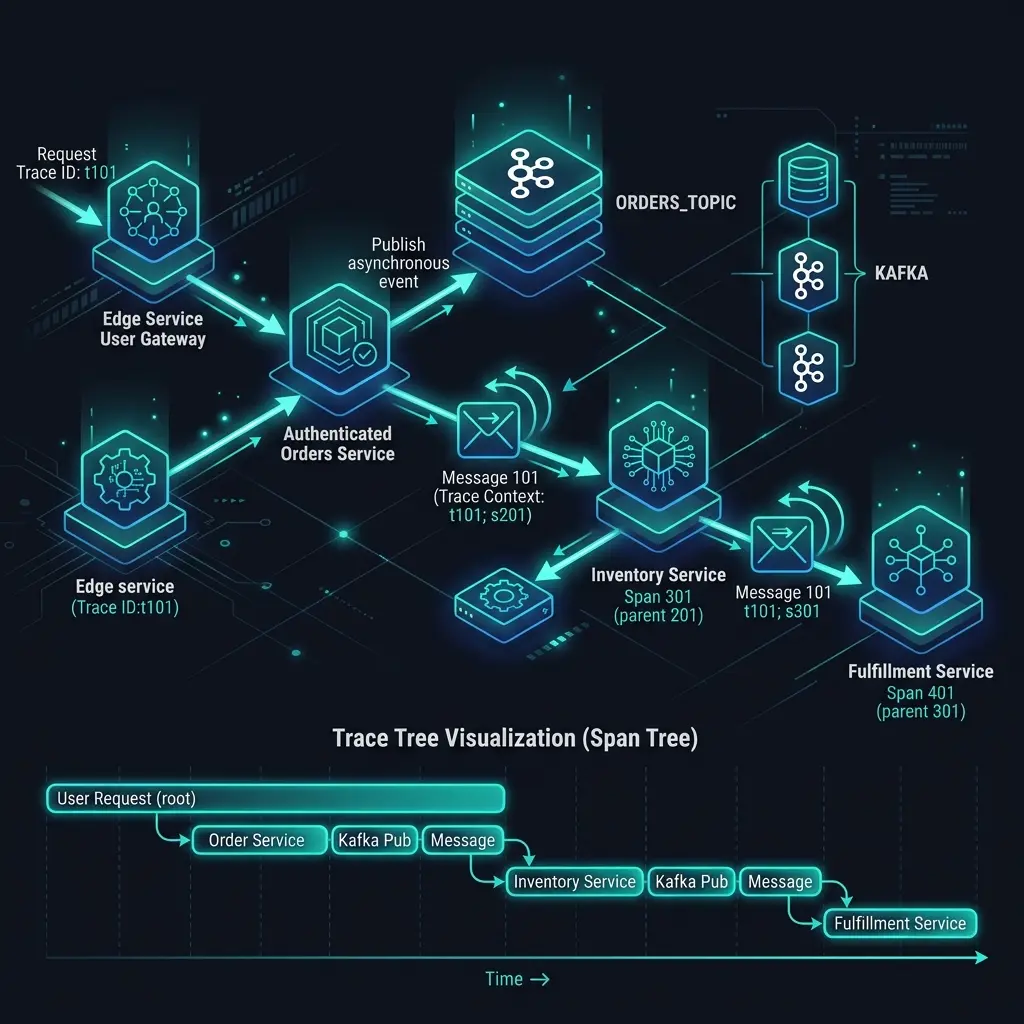
El tracing distribuido funciona de maravilla en sistemas síncronos. Haces una llamada HTTP, el contexto de traza se propaga a través de la cabecera traceparent, y al otro lado ves un árbol de spans limpio que te cuenta exactamente qué ha pasado.
Ahora añade una cola de mensajes.
De repente la traza se rompe. El servicio consumidor arranca un nuevo span raíz. Tu topic de Kafka se convierte en un agujero negro de observabilidad. Puedes ver que se publicó un mensaje y puedes ver que eventualmente fue procesado, pero has perdido el vínculo causal entre ellos. En producción, cuando un job de procesamiento de mensajes va lento o falla, estás volando a ciegas.
Este es uno de los gaps de observabilidad más comunes que encuentro en sistemas distribuidos. La buena noticia es que tiene solución — pero requiere entender primero por qué se rompe.
Por qué se pierde el contexto de traza en las colas
El tracing HTTP funciona porque las cabeceras viajan con la petición. La cabecera traceparent lleva el trace ID y el parent span ID, y todos los SDKs de OpenTelemetry saben cómo extraerla automáticamente.
Las colas de mensajes no tienen este mecanismo por defecto. Cuando publicas un mensaje en Kafka, estás serializando un payload — no una petición HTTP. A menos que inyectes explícitamente el contexto de traza en las cabeceras del mensaje, desaparece.
El patrón es el siguiente:
// SIN propagación de traza — el contexto se pierde
producer.send(ProducerRecord("orders", orderData)) // contexto de traza no incluido
// CON propagación de traza — el contexto viaja con el mensaje
val headers = mutableMapOf<String, String>()
val propagator = GlobalOpenTelemetry.getPropagators().textMapPropagator
propagator.inject(Context.current(), headers) { map, key, value -> map[key] = value }
val record = ProducerRecord<String, ByteArray>("orders", null, orderData).also { rec ->
headers.forEach { (key, value) ->
rec.headers().add(key, value.toByteArray())
}
}
producer.send(record)En el lado consumidor, necesitas extraerlo:
import io.opentelemetry.api.GlobalOpenTelemetry
import io.opentelemetry.api.trace.SpanKind
import io.opentelemetry.context.Context
import io.opentelemetry.context.propagation.TextMapGetter
val headerGetter = TextMapGetter<Headers> {
headers, key -> headers.lastHeader(key)?.value()?.let { String(it) }
}
fun processMessage(record: ConsumerRecord<String, ByteArray>) {
val propagator = GlobalOpenTelemetry.getPropagators().textMapPropagator
val parentContext = propagator.extract(Context.current(), record.headers(), headerGetter)
val span = tracer.spanBuilder("orders.process")
.setParent(parentContext)
.setSpanKind(SpanKind.CONSUMER)
.startSpan()
span.use {
it.setAttribute("messaging.system", "kafka")
it.setAttribute("messaging.destination", record.topic())
it.setAttribute("messaging.kafka.partition", record.partition().toLong())
// procesar el mensaje...
}
}Esto te da una traza conectada. El span consumidor se convierte en hijo del span productor, y puedes ver el flujo completo desde la petición HTTP original hasta el procesamiento final, pasando por la cola.
El problema con los consumidores de larga duración
Hay un problema más sutil que pilla desprevenidos a la mayoría de equipos: el tiempo de vida del span vs. el tiempo de procesamiento del mensaje.
Cuando tienes un consumidor que corre indefinidamente, sacando mensajes en bucle, necesitas decidir dónde empiezan y acaban tus spans. El enfoque instintivo — un span para todo el bucle consumidor — está mal. Produce un único span que corre durante horas sin información útil dentro.
El modelo correcto es un span por mensaje:
fun consumeLoop(consumer: KafkaConsumer<String, ByteArray>) {
while (true) {
val records = consumer.poll(Duration.ofMillis(100))
for (record in records) {
// Extraer contexto de este mensaje específico
val parentContext = propagator.extract(
Context.current(), record.headers(), headerGetter
)
// Nuevo span para cada mensaje — enlazado al contexto productor
val span = tracer.spanBuilder("order.process")
.setParent(parentContext)
.setSpanKind(SpanKind.CONSUMER)
.startSpan()
try {
span.makeCurrent().use {
handleOrder(record.value())
span.setStatus(StatusCode.OK)
}
} catch (e: Exception) {
span.recordException(e)
span.setStatus(StatusCode.ERROR)
} finally {
span.end()
}
}
}
}Cada mensaje obtiene su propia rama de traza, enraizada en el contexto productor original. Esto significa que puedes buscar todos los spans relacionados con un order ID específico, ya ocurran en un handler HTTP, un consumidor Kafka, o un worker en background.
Causalidad rota en patrones fan-out
Las cosas se complican cuando un mensaje desencadena múltiples mensajes downstream. Supón que un evento order.created genera tres mensajes separados: uno a inventario, uno a pagos, uno a notificaciones.
En una implementación naive, cada una de esas trazas downstream está completamente desconectada. En tu backend de tracing, verás cuatro trazas separadas sin ninguna relación visible.
La solución es usar span links — una forma de expresar relaciones entre spans de diferentes trazas:
import io.opentelemetry.api.trace.SpanContext
fun handleOrderCreated(record: ConsumerRecord<String, ByteArray>) {
val parentContext = propagator.extract(
Context.current(), record.headers(), headerGetter
)
val parentSpanContext = Span.fromContext(parentContext).spanContext
// Crear un link de vuelta al evento de orden original
val span = tracer.spanBuilder("inventory.reserve")
.addLink(parentSpanContext)
.setSpanKind(SpanKind.PRODUCER)
.startSpan()
span.use {
val orderId = objectMapper.readTree(record.value())["id"].asText()
sendInventoryMessage(orderId)
}
}Los span links están soportados en Jaeger y Tempo, pero no todos los backends los renderizan bien. Consulta la documentación de tu backend de tracing antes de depender de ellos.
Timing y desfase de relojes
Algo que te confundirá: las marcas de tiempo en tus trazas asíncronas parecerán incorrectas.
Un mensaje publicado a las 10:00:00 puede aparecer en la traza como procesado a las 09:59:58 — dos segundos antes de ser enviado. Esto es desfase de reloj entre los hosts productor y consumidor. Es normal, pero hace que las vistas de cascada en las UIs de tracing sean muy confusas.
La solución práctica: no te fíes de las marcas de tiempo absolutas para spans asíncronos. Usa los atributos messaging.kafka.offset y messaging.kafka.partition para establecer el orden. Y documenta a tu equipo que el timing de spans asíncronos es aproximado.
Atributos que realmente ayudan
Cuando estés depurando un consumidor lento en producción, estos son los atributos que desearás haber añadido:
span.setAttribute("messaging.system", "kafka")
span.setAttribute("messaging.destination", topic)
span.setAttribute("messaging.operation", "process")
span.setAttribute("messaging.kafka.partition", partition.toLong())
span.setAttribute("messaging.kafka.offset", offset)
span.setAttribute("messaging.kafka.consumer_group", groupId)
// Contexto de negocio
span.setAttribute("order.id", orderId)
span.setAttribute("order.amount", amount)
span.setAttribute("order.currency", currency)Los atributos messaging.* siguen las convenciones semánticas de OpenTelemetry para sistemas de mensajería. Seguirlas significa que tus spans serán compatibles con cualquier herramienta que entienda OTel.
El enfoque pragmático
Si estás añadiendo tracing a un sistema existente con muchos consumidores, no intentes arreglarlo todo a la vez. Prioriza:
- Topics de alto volumen y alto valor primero — eventos de pago, eventos de pedidos, todo lo que causa problemas visibles al cliente
- Topics donde hayas tenido incidentes — instrumenta donde duele
- Puntos de fan-out — cualquier lugar donde un mensaje produce muchos mensajes downstream es un punto ciego que vale la pena arreglar
La observabilidad asíncrona es genuinamente más difícil que el tracing síncrono, pero la brecha es salvable. Los equipos con los que trabajo que invierten en ello ven cómo su tiempo medio de diagnóstico cae significativamente — porque finalmente pueden seguir una interacción de cliente a través de todos los servicios que toca, con cola o sin ella.