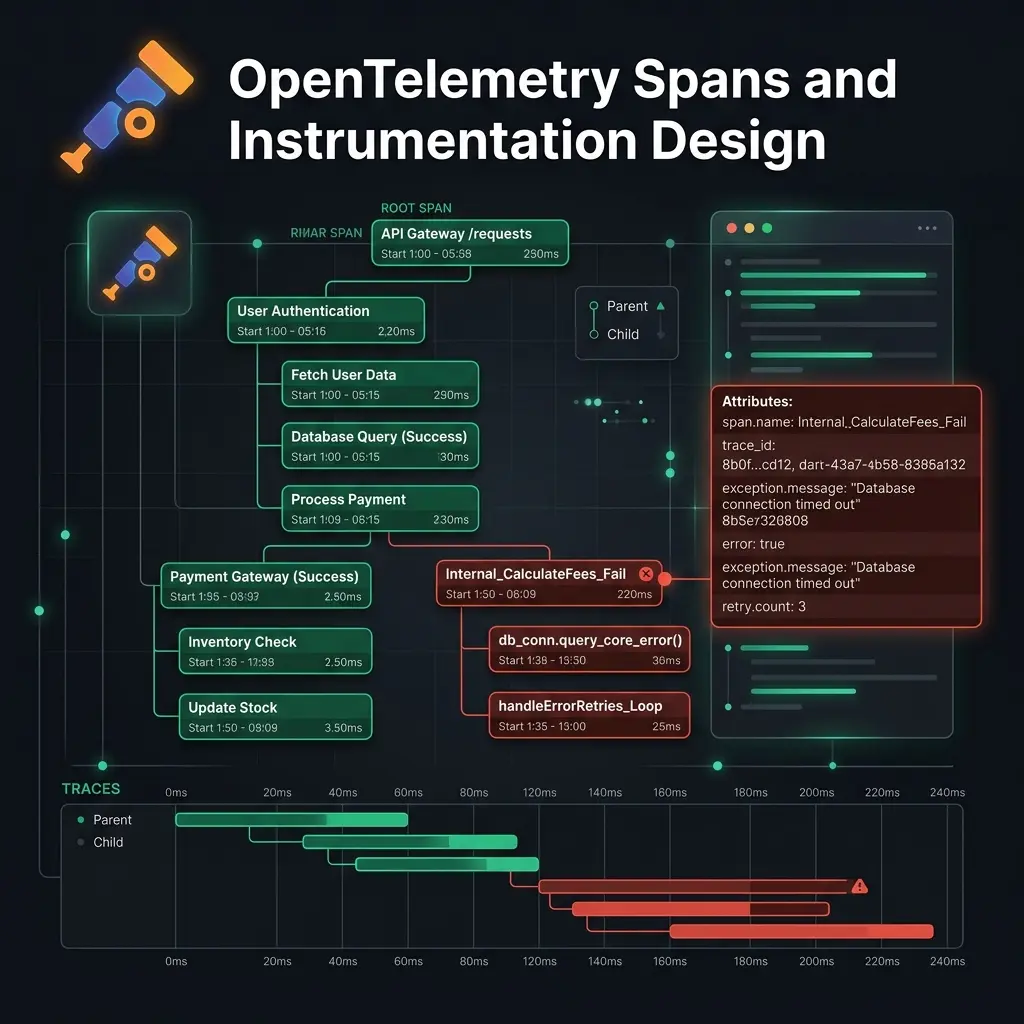
La mayoría de equipos con los que trabajo tienen el mismo problema: han instrumentado sus servicios con OpenTelemetry, tienen trazas fluyendo hacia su backend y, sin embargo — cuando algo se rompe en producción — las trazas no les ayudan a encontrar el problema.
Esto no es un problema de OpenTelemetry. Es un problema de diseño.
La trampa de la instrumentación
Cuando los ingenieros descubren OpenTelemetry por primera vez, la reacción es casi siempre la misma: instrumentar todo. Añadir spans a cada función, cada llamada a base de datos, cada petición HTTP. Más datos significa más visibilidad, ¿verdad?
No exactamente.
El problema de instrumentar todo es que terminas con una traza que parece un call stack — cientos de spans, anidados cinco niveles de profundidad, cada uno nombrado según una función o un método de clase. Técnicamente es una traza, pero no son datos de observabilidad útiles.
// Lo que hace la mayoría: instrumentar la implementación
tracer.spanBuilder("UserService._loadUserFromCache").startSpan().use {
user = cache.get(userId)
}
tracer.spanBuilder("UserService._queryDatabase").startSpan().use {
user = db.query("SELECT * FROM users WHERE id = ?", userId)
}Esto te da datos de timing de tus funciones internas. Raramente es lo que necesitas al depurar un incidente en producción.
Qué deberían decirte los spans
Un span bien diseñado debería responder una pregunta de negocio, no describir un detalle de implementación. El cambio clave es pasar de “¿qué está haciendo el código?” a “¿qué está haciendo el sistema?”
| Nombre de span malo | Nombre de span bueno |
|---|---|
UserService._loadFromDb | user.fetch |
CacheManager.get | cache.lookup{resource=user} |
HttpClient.execute | GET /api/users/{id} |
JSONSerializer.serialize | (no merece un span) |
Los buenos nombres describen qué ocurrió en términos que tu equipo pueda entender durante un incidente, no cómo funciona el código internamente.
Las tres preguntas que todo span debería responder
Antes de añadir un span, pregúntate:
- ¿Me ayudaría este span durante un incidente? Si no puedes imaginar un escenario donde agradecieras que existiera este span a las 3am, no lo añadas.
- ¿Representa este span una unidad de trabajo significativa? Los spans deben mapear a algo que una persona no técnica pudiera entender — “obtener usuario”, “enviar email”, “procesar pago” — no “llamar método”.
- ¿Tiene este span atributos útiles? Un span sin contexto es casi inútil. Si añades un span
user.fetch, asegúrate de que llevauser.id,db.namey si fue un cache hit.
Los atributos importan más que los spans
Aquí está lo que la mayoría de equipos hace mal: el valor de una traza no está en los spans en sí — está en los atributos adjuntos a esos spans.
tracer.spanBuilder("user.fetch").startSpan().use { span ->
span.setAttribute("user.id", userId)
span.setAttribute("db.name", "users_primary")
span.setAttribute("cache.hit", false)
val user = db.fetchUser(userId)
span.setAttribute("user.tier", user.subscriptionTier)
span.setAttribute("user.region", user.region)
user
}Ahora, cuando depuras un pico de latencia, puedes filtrar por user.region = "eu-west" o user.tier = "free" e inmediatamente determinar si el problema afecta a todos los usuarios o a un segmento específico.
Una heurística práctica
Al revisar instrumentación, uso esta regla: un span por límite de I/O, más spans para operaciones de negocio significativas.
- Cada llamada HTTP externa: un span
- Cada consulta de base de datos (no cada consulta en un bucle): un span por operación lógica
- Cada operación de caché (check + set): un span
- Procesamiento de pagos, creación de pedidos, envío de emails: un span cada uno
- Llamadas a métodos internos, serialización JSON, manipulación de strings: ningún span
Un servicio Kotlin bien estructurado podría quedar así:
class OrderService(private val tracer: Tracer) {
fun processOrder(orderId: String, userId: String): Order {
// UN span para la operación de negocio
return tracer.spanBuilder("order.process")
.startSpan()
.use { span ->
span.setAttribute("order.id", orderId)
span.setAttribute("user.id", userId)
// Métodos internos — no hacen falta spans extra
val order = fetchOrder(orderId)
validateOrder(order)
// UN span por límite de I/O externo
val payment = chargePayment(order) // tiene su propio span dentro
notifyWarehouse(order) // tiene su propio span dentro
span.setAttribute("order.amount", order.totalAmount)
span.setAttribute("payment.id", payment.id)
order
}
}
private fun chargePayment(order: Order): Payment {
return tracer.spanBuilder("payment.charge")
.setSpanKind(SpanKind.CLIENT)
.startSpan()
.use { span ->
span.setAttribute("payment.provider", "stripe")
span.setAttribute("payment.amount", order.totalAmount)
paymentGateway.charge(order)
}
}
}Esto mantiene tus trazas legibles y tus costes de almacenamiento de trazas manejables.
Conclusión
La observabilidad efectiva no consiste en recopilar más datos — sino en recopilar los datos correctos. Empieza definiendo qué preguntas necesitas responder durante los incidentes, luego diseña tu instrumentación para responder esas preguntas.
Si puedes ver una traza durante un incidente en producción y entender inmediatamente qué estaba haciendo el sistema, qué llamadas externas fueron lentas y qué contexto de usuario estaba involucrado — tu instrumentación es buena. Si estás mirando una pared de nombres de funciones anidadas, empieza de nuevo.