Has puesto el límite de memoria de tu contenedor en 2GB. Tu heap JVM está configurado en 1GB con -Xmx1g. Los números cuadran. Y sin embargo, cada pocos días tu pod muere por OOM kill.
Este es uno de los problemas en producción más comunes — y más malentendidos — en cargas de trabajo JVM containerizadas. El problema no es el heap. Es todo lo demás.
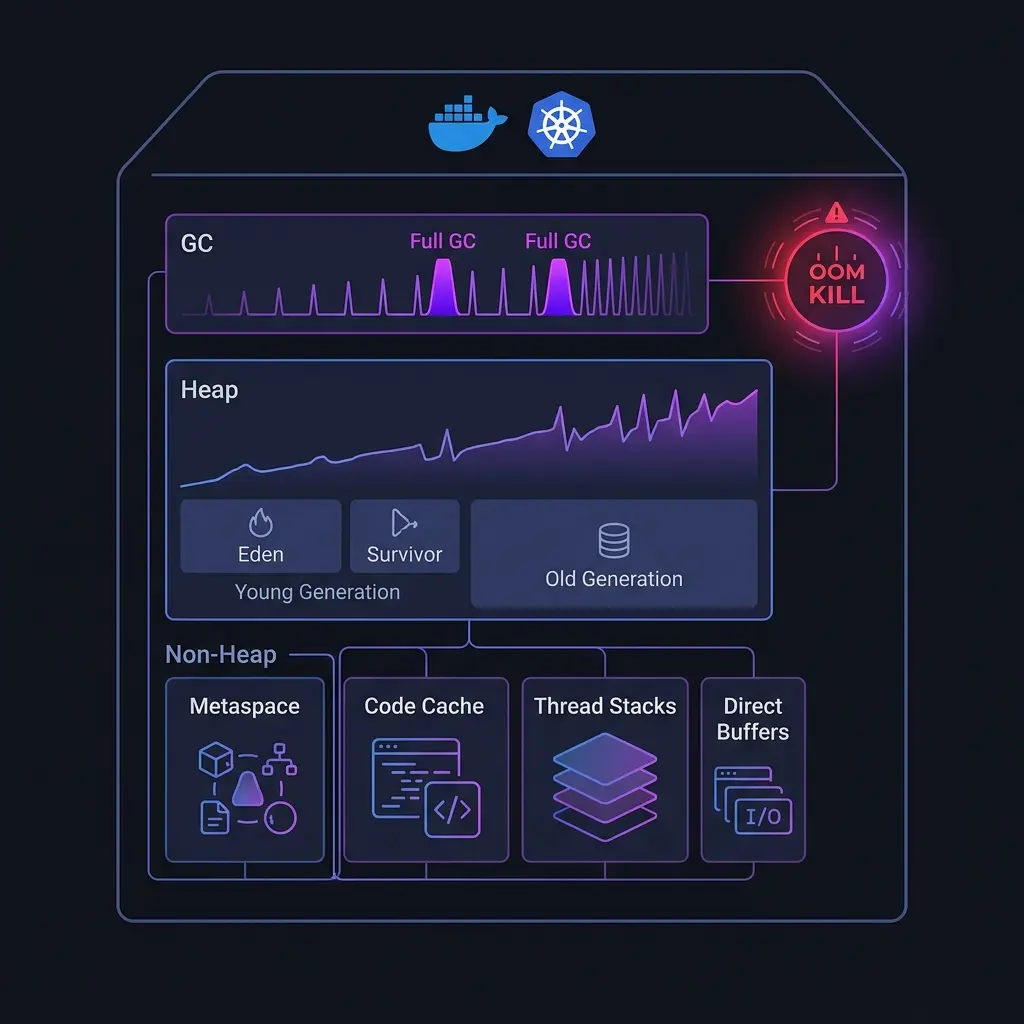
La memoria que la JVM no te cuenta
El uso del heap JVM, visible en tus métricas jvm.memory.used, es solo una parte del panorama. Un proceso JVM en ejecución consume memoria en varias regiones, la mayoría de las cuales son invisibles para el monitoreo estándar:
| Región | Qué contiene |
|---|---|
| Heap | Objetos, lo que controla -Xmx |
| Metaspace | Metadatos de clases, bytecode cargado |
| Code cache | Código nativo compilado por JIT |
| Thread stacks | Una pila por thread, ~512KB–1MB cada una |
| Direct buffers | Memoria off-heap de NIO, usada por código de red |
| Ficheros mapeados | Archivos memory-mapped, librerías nativas |
| Internos de JVM | Estructuras de datos del GC, tablas de símbolos |
Cuando el OOM killer de tu contenedor actúa, está mirando el tamaño total del resident set (RSS) del proceso — la suma de todo esto. Una JVM usando 1GB de heap puede tener fácilmente 1.4–1.6GB de RSS total, y con un límite de contenedor de 2GB, no tienes mucho margen.
Cómo encontrar qué está usando realmente la memoria
El primer paso es obtener visibilidad de todas las regiones de memoria, no solo del heap.
Añade métricas de memoria JVM a tu telemetría existente. Si usas OpenTelemetry, el agente de instrumentación JVM captura automáticamente:
jvm.memory.used{area="heap"}
jvm.memory.used{area="nonheap"} # metaspace + code cache
jvm.thread.count
jvm.gc.collections.elapsedPero aún no es suficiente para depurar OOMs. Necesitas métricas a nivel de proceso:
# RSS de tu proceso JVM
cat /proc/<pid>/status | grep VmRSS
# Mapa de memoria detallado
cat /proc/<pid>/smaps_rollupO con herramientas nativas de JVM:
# Native memory tracking — añade esto a los flags de JVM
-XX:NativeMemoryTracking=summary
# Luego consúltalo en tiempo de ejecución
jcmd <pid> VM.native_memory summaryLa salida de VM.native_memory te mostrará exactamente cuánta memoria consume cada subsistema de JVM. A menudo encontrarás sorpresas aquí.
También puedes consultar los memory pools programáticamente desde tu aplicación Kotlin/Java:
import java.lang.management.ManagementFactory
fun printMemoryStats() {
val memBean = ManagementFactory.getMemoryMXBean()
val heapUsage = memBean.heapMemoryUsage
val nonHeapUsage = memBean.nonHeapMemoryUsage
println("Heap usado: ${heapUsage.used / 1024 / 1024} MB / ${heapUsage.max / 1024 / 1024} MB")
println("Non-Heap usado: ${nonHeapUsage.used / 1024 / 1024} MB")
ManagementFactory.getMemoryPoolMXBeans().forEach { pool ->
val usage = pool.usage
println("${pool.name}: ${usage.used / 1024 / 1024} MB usado")
}
}La trampa del Metaspace
El Metaspace es donde la JVM almacena los metadatos de clases. A diferencia del antiguo PermGen, por defecto no tiene límite superior fijo — crece hasta que el SO dice que no.
En entornos containerizados, esto significa que el Metaspace puede crecer silenciosamente hasta llenar toda la memoria disponible. Suele ocurrir cuando:
- Usas generación dinámica de clases (frameworks pesados en reflexión, manipulación de bytecode)
- Tienes leaks de classloader (común en apps que recargan código dinámicamente)
- Usas un framework que genera clases proxy al arrancar (Spring, Hibernate)
Pon un límite explícito:
-XX:MaxMetaspaceSize=256mEsto causará un OutOfMemoryError: Metaspace en lugar de un OOM kill silencioso — lo que en realidad es mejor, porque es detectable y alertable.
Para diagnosticar si el Metaspace está creciendo inesperadamente:
jcmd <pid> VM.native_memory summary | grep MetaspaceSi lo ves crecer durante días en un proceso de larga duración, probablemente tienes un leak de classloader.
Tormentas de GC y límites de CPU del contenedor
El comportamiento del GC en contenedores se complica con los límites de CPU. Por defecto, la ergonomía de JVM (el sistema que autoconfigura la JVM basándose en los recursos disponibles) lee el número de CPUs para determinar el número de threads de GC. En un contenedor con 8 CPUs del host pero un límite de 2 CPUs, la JVM podría lanzar igualmente 8 threads de GC — que luego son throttleados por el límite de CPU, convirtiendo las pausas de GC de milisegundos en segundos.
Solución: configura explícitamente los thread counts del GC y usa flags de JVM compatibles con contenedores:
# Compatibilidad con contenedores (activado por defecto en JDK 8u191+, JDK 10+)
-XX:+UseContainerSupport
# Thread counts explícitos de GC relativos al límite de CPU
-XX:ParallelGCThreads=2
-XX:ConcGCThreads=1
# Usa G1GC para la mayoría de cargas de trabajo de servidor
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200Para ver qué cree la JVM que tiene disponible:
java -XX:+PrintFlagsFinal -version 2>&1 | grep -E "ActiveProcessor|GCThreads"También puedes comprobarlo en tiempo de ejecución desde Kotlin:
import java.lang.management.ManagementFactory
fun printGcStats() {
val runtime = Runtime.getRuntime()
println("Procesadores disponibles: ${runtime.availableProcessors()}")
ManagementFactory.getGarbageCollectorMXBeans().forEach { gc ->
println("GC: ${gc.name}, colecciones: ${gc.collectionCount}, tiempo: ${gc.collectionTime}ms")
}
}Diagnosticando leaks off-heap
Los leaks de memoria off-heap son los más difíciles de encontrar porque tus métricas de heap parecen estar bien. El proceso sigue creciendo, el GC corre normalmente, pero el RSS sube poco a poco hasta que el OOM killer actúa.
Culpables habituales:
Direct ByteBuffers — reservados con ByteBuffer.allocateDirect(), comunes en frameworks basados en Netty (Vert.x, Quarkus reactivo, gRPC). No son recolectados por el GC normal:
# Rastrear uso de direct buffers
jcmd <pid> VM.native_memory summary | grep "Internal"Puedes monitorear el uso de direct buffers desde tu aplicación:
import java.lang.management.ManagementFactory
import javax.management.ObjectName
fun getDirectBufferUsage(): Long {
val mbs = ManagementFactory.getPlatformMBeanServer()
val name = ObjectName("java.nio:type=BufferPool,name=direct")
return mbs.getAttribute(name, "MemoryUsed") as Long
}Librerías JNI — el código nativo llamado vía JNI gestiona su propia memoria fuera de la JVM. Los leaks aquí son invisibles para toda la tooling de JVM y requieren profiling a nivel nativo con herramientas como Valgrind o Heaptrack.
Ficheros memory-mapped — frameworks como Chronicle Map, RocksDB, o MapDB usan mmap. Estos aparecen en el RSS pero no en las métricas de heap.
Para un proceso en producción, puedes obtener un snapshot del mapa de memoria:
cat /proc/<pid>/smaps | grep -E "^(Size|Rss|Anonymous)" | \
awk '/Size/{s=$2} /Rss/{r=$2} /Anonymous/{a=$2; print s, r, a}' | \
sort -rn -k2 | head -20Esto muestra las 20 regiones de memoria más grandes por RSS, lo que a menudo apunta directamente al leak.
Una fórmula práctica de dimensionado
Cuando dimensiono contenedores JVM, uso esta fórmula como punto de partida:
Límite contenedor = Xmx + 400MB (metaspace + code cache)
+ (número de threads × 1MB) (thread stacks)
+ 200MB (direct buffers, internos JVM)
+ 20% margenPara un servicio típico con -Xmx1g, 100 threads y uso moderado de direct buffers:
1024 + 400 + 100 + 200 = 1724MB × 1.2 = ~2.1GBPon el límite del contenedor en 2.5GB y tu -Xmx en 1GB. Ese gap de 500MB no es desperdicio — es el espacio que la JVM necesita para operar sin que la maten.
Las métricas sobre las que alertar
Una vez que tienes visibilidad en todas las regiones de memoria, configura alertas sobre:
- Uso off-heap (
jvm.memory.used{area=nonheap}acercándose a su máximo) - Overhead de GC — si más del 5% del tiempo de CPU se gasta en GC, tienes un problema
- Duración de pausas de GC — pausas p99 por encima de 500ms afectan tu latencia de cola
- Uso de memoria del contenedor — alerta al 80% del límite, no al 95%
Ese último punto es crítico. Para cuando el uso de memoria llega al 95% del límite del contenedor, tienes segundos antes del OOM kill. Al 80%, tienes tiempo para investigar, escalar o limpiar cachés.
La JVM es un runtime extraordinariamente bien instrumentado — pero solo si sabes dónde mirar. La mayoría de equipos instrumenta el heap y pierde todo lo demás. No seas ese equipo a las 3am cuando tus pods empiezan a morir.